essentiaの特徴
データレイクの構築に最適なソフトウェア
Software Design Summary
-

ファイルベースのデータを
高速に加工・集計処理特にタイムシリーズデータ(ログ)の処理、キー単位の名寄せ処理を得意としています。
-

Linux上で動作する
コマンドラインで構成され、
Shell Scriptで記述が可能クラスタの起動、停止からデータロード、インメモリデータ処理まで全てをShellで記述・実行が可能です。
-

インメモリ・並列分散処理・
ストリーミングロードインメモリデータベースは、データの処理を行う際、HDDに書き出す必要がなく、かつソースデータをロードしながら、同時に加工処理を実行することで、非構造データやタイムシリーズデータ処理の高速化を実現。
-

Public Cloud
(AWS, Microsoft Azure)での
利用を意識した設計思想必要な時に環境を構築し、処理を実行、処理が完了し、必要なくなったらインスタンスを落とすことでコストを削減、オンプレミスでの利用も可能です。
-

シンプルな構造、
高い拡張性環境構築やデータ処理の実装において、ソフトウェアを用いたシンプルな構造で、導入期間やコスト、負荷の削減を実現します。
01 技術的優位性 ストリーミングロード
essentiaは元データの形式のままクラウドストレージにアップロードするだけで、アプリケーションがダイレクトに並列分散で読み込み処理を実行します。一般的なデータ処理フローにおいて、必要とされる中間プロセスは一切不要です。
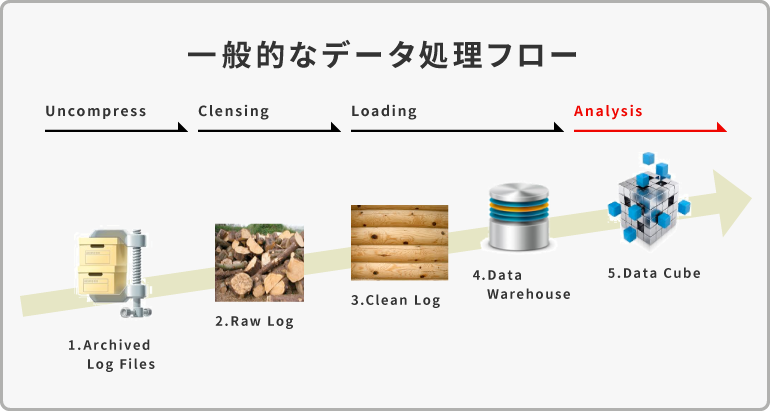
一般的なデータベースは、圧縮ファイルを解凍→クレンジング→DWHに格納→加工・集計とデータ処理に際して、何段階ものプロセスが必要です。

essentiaは、元データの形式のままクラウドストレージにアップロードするだけで、ダイレクトに並列分散でストリーミングロードし、並列分散でデータの加工・処理・集計を実行します。
02
技術優位性 インメモリ
(ローディングとデータマージ)
一般的なシステムでは①②③の全レコードをデータベースにロードしてから、データ処理を実行しますが、essentiaはデータをロードしながら同時に対象ユーザへの絞り込み処理を実行します。不要なデータは読み込まないため、データロードの時間を大幅に短縮し、同時にデータ処理上のオーバーヘッドを削減することができるのです。
(ローディングMerge・JOIN技術)
Case : コンバージョンユーザの広告接触とWebログ分析データの生成
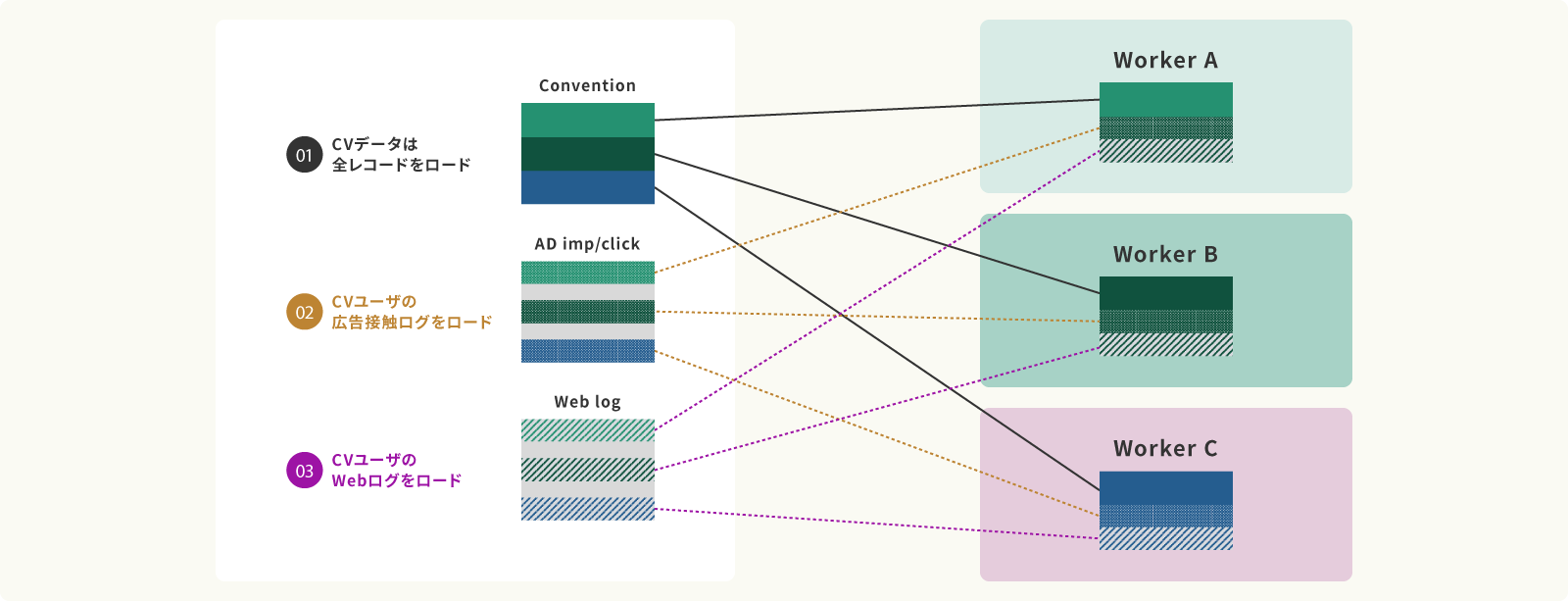
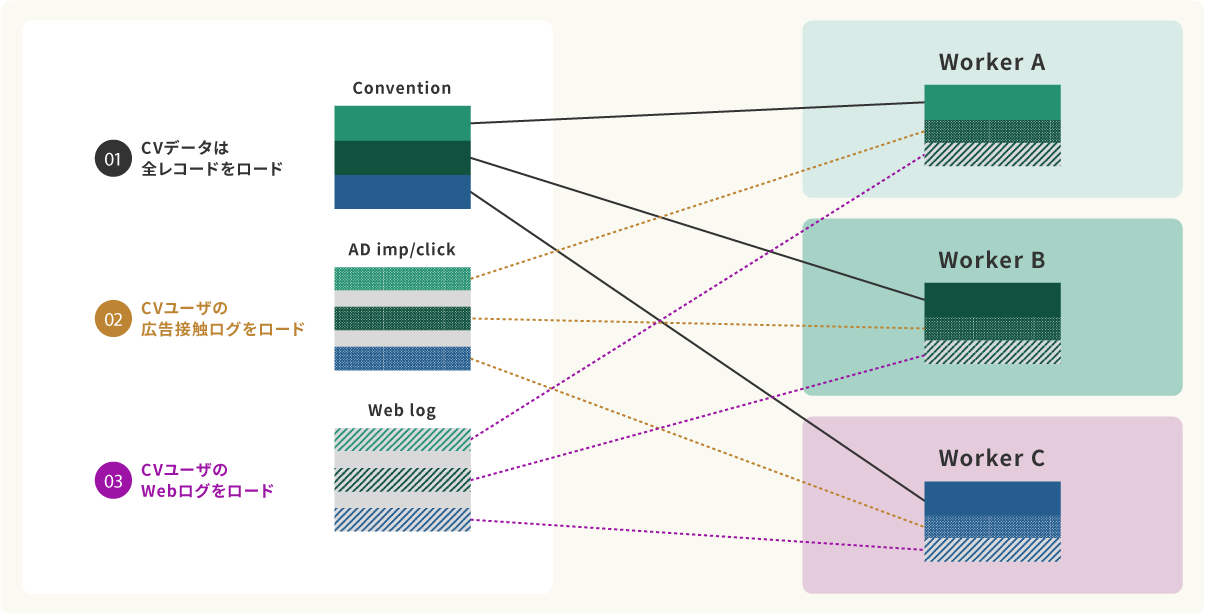
図は広告配信ログデータ、数百億件分をロードし、コンバージョンしたユーザの広告接触履歴、Webサイト訪問履歴を作成するデータ処理を実行した例です。①でコンバージョンしたユーザの全データをロードした後は、②③のデータ処理のプロセスではコンバージョンしていないユーザのデータは読み飛ばして処理を行います。例え、データ量が幾何級数的に増えて、数千億件になったとしても、ユーザの初回接触からコンバージョンに至るまでのカスタマージャーニーデータを容易に生成することができるのです。
03
技術優位性 並列分散処理
(essentiaクラスター)
essentiaはデータロードとデータ処理の両方のプロセスで並列分散処理を実現しています。マスタはワーカーへのジョブの割り当て、処理完了後のデータのマージ(いわゆるReduce)機能を受け持ちます。各ワーカーは担当のジョブのみを実行し、他のワーカーのジョブには関与しません。並列分散の台数の上限はなく、データ量や処理の頻度、求められる処理速度に応じた柔軟なリソース設計が可能な仕組みになっています。
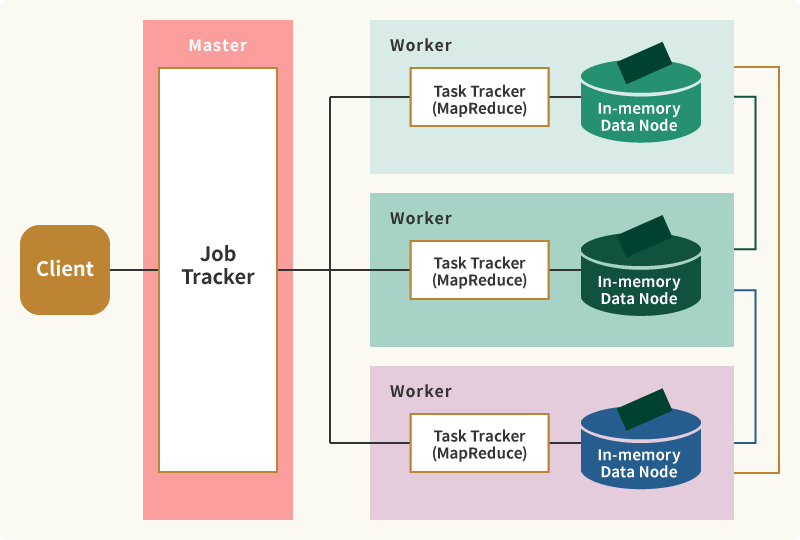
essentiaクラスタは、Masterノード, Workerノードで構成されています。Masterノードは、クライアントから命令されたJOBをWorkerノードに割り振る機能とファイル出力時のReduce機能を受け持ちます。Workerノードは、Masterから割り振られた処理を実行する機能とインメモリ・データストアの機能を持っています。データの分散配置や再配置処理など、Workerノード間で可能な通信は、Masterノードを介さずに実行され、効率的なネットワークパスを実現しています。
04
技術的優位性
インメモリデータベース
essentiaのデータ処理プロセスイメージ
S3にオリジナルの形式でデータを配置しておくだけで、後はすべてのデータ処理プロセスをessentiaのソフトウェアが実行します。
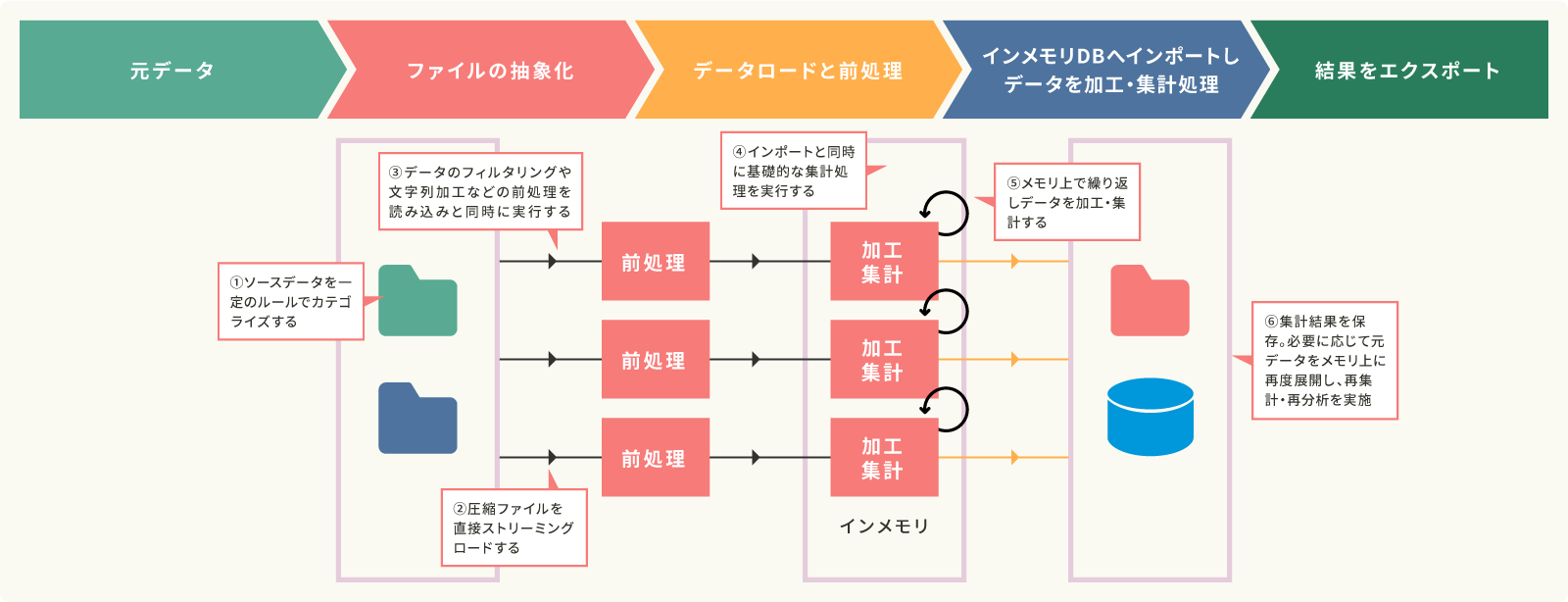
essentiaのデータ処理詳細(前処理とデータ加工・集計処理)
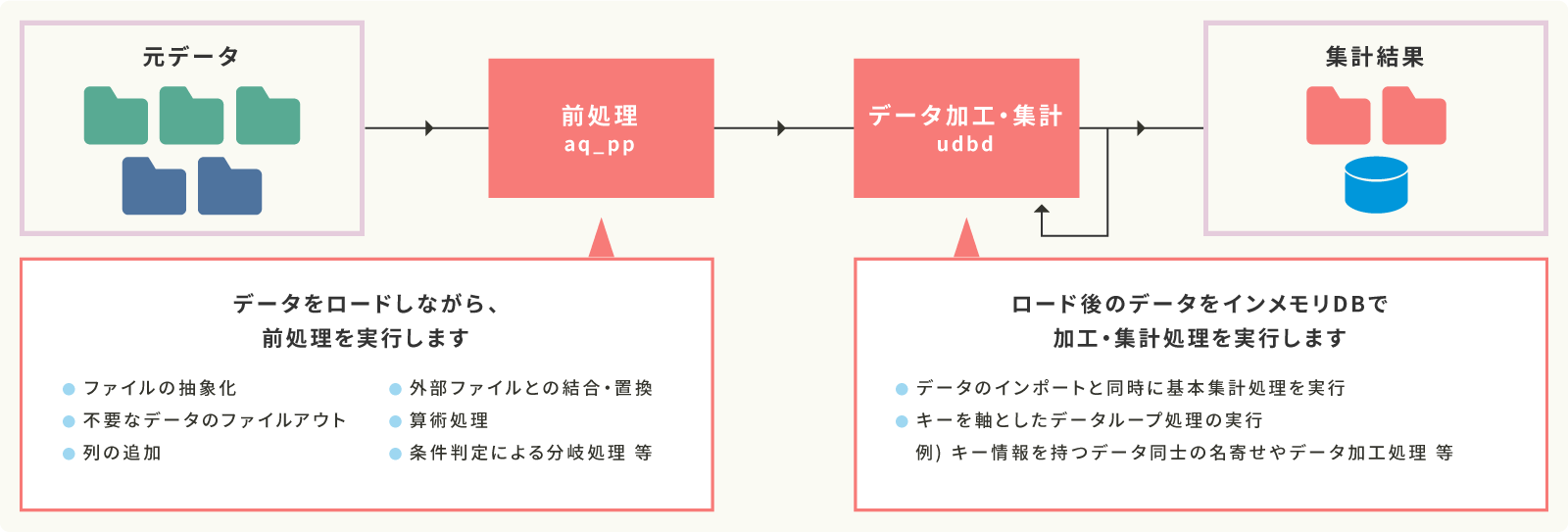
05 技術的優位性 キーを軸にしたデータの分散
essentiaはデータを各ノードで分散保持することで、1ノードあたりの処理対象レコード数を減らして高速化を実現しています。各ノードはキーを軸にデータを分散しています。
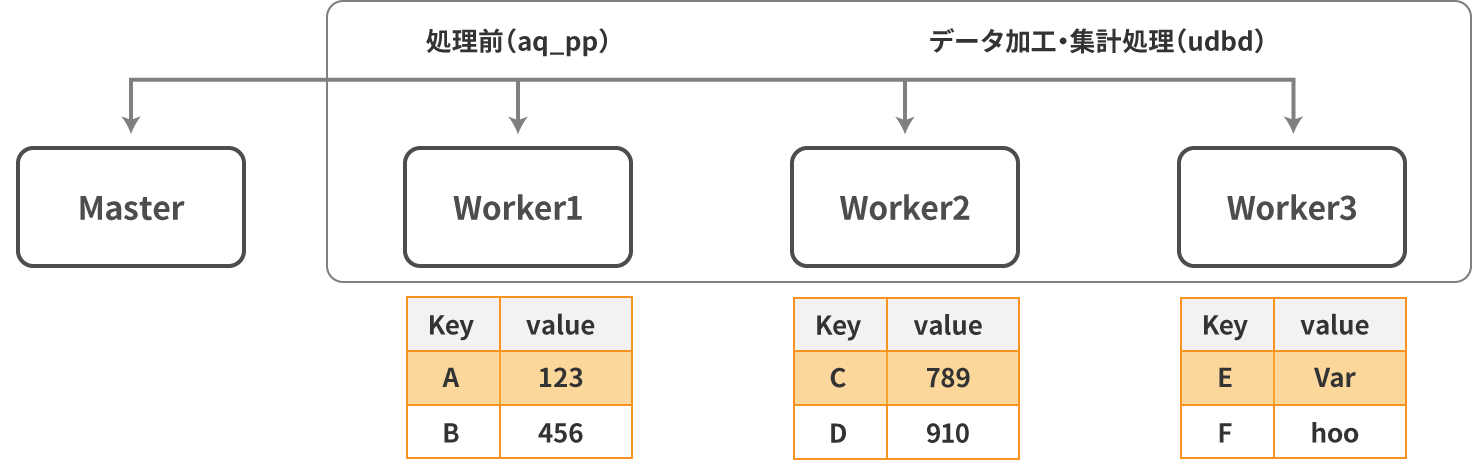
各ノードは自身が担当するデータのみを処理対象にし、他のノードを参照する必要がないため、IOコストが低く抑えられ、データ処理の高速化を実現しています。処理したデータを更に別のキーを定義したデータオブジェクトへインポートし直す場合、キーを軸にしたデータの再配置を実行するため、ノード間のデータ送受信が発生します。
ベンチマーク比較 essentia vs Redshift
| 現状の課題 | データ概要 |
|---|---|
|
処理時間の短縮 処理内容の高度化 →特に処理時間の短縮が緊急課題 |
対象データ:ディスプレイ広告配信ログ データ期間:1か月間 データサイズ:約9TB(圧縮状態1.55TB) データ形式:gz圧縮TSV、約4万ファイル イベント数:約230億レコード ユニークユーザ(cookie)数:約2億 プラットフォーム:AWS-Tokyo |
| 集計内容 |
|---|
|
1 全期間で広告No×入札成功/失敗別にユニークユーザ数と入札数を集計
*1 OS、ブラウザはUserAgentから抽出しUserAgenet -OS-BWの対応マスターを作成 |
| ベンチマーク結果 | essentia | Redshift | |||
|---|---|---|---|---|---|
| 使用Node | m5.xlarge | dc1.8xlarge | |||
| 集計内容 | 集計No. | time | node | time | node |
| 1 | 55m | 100 | 1h09m | 8 | |
| 2 | 100 | 2h00m | 8 | ||
| 3 | 100 | 1h25m | 8 | ||
| 4 | 100 | 1h16m | 8 | ||
| 処理時間 | 55m | 6h | |||
| データロード時間 | 24h | ||||
| AWS使用金額 | $22.73 | $182.85 | |||
処理性能結果
同様の処理を実施し、Redshiftと比較
データオブジェクト
essentiaのインメモリデータ処理では、以下の2種類のデータオブジェクトを定義できます。
| 種類 | 主な用途・特徴 |
|---|---|
| table |
キーごとに複数行のデータを保持します。 主に、データをそのまま格納し、後から参照するために使用します。 |
| vector |
キーごとに単一行のデータを保持します。 キー以外の項目に集計処理が設定でき、インポートするだけで設定した集計処理が行われます。 |
各オブジェクトには必ず1つのキーが設定されています。同じキーのデータオブジェクトはdatabaseとしてグループ化され、データをインポートした時点でキーでJOINされた状態を形成します。vectorの項目には以下の集計処理が設定できます。集計処理はデータのインポート時点で実行され、インポート完了と同時に集計が完了します。
| 種類 | 主な用途・特徴 |
|---|---|
| +FIRST | インポートされた最初の値を保持します。 |
| +LAST | インポートされた最後の値を保持します。 |
| +ADD | インポートされた値を加算します。 |
| +MIN | インポートされた値の最小値を保持します。 |
| +MAX | インポートされた値の最大値を保持します。 |
| +NOZERO | 数値型の場合は0ではなく値を、文字列型の場合は空白ではない値を保持します。 +FIRST、+LAST、+MIN、+MAXと併用します。 |
essentiaは以下の
2つの方法でご利用頂けます。
処理対象とするデータの種類や機密性、プロジェクトのフェーズ、お客様のデータセキュリティのポリシー等から、適切な方法をお選び下さい。
クラウドサービスでPoCを実施した後、サブスクリプションに環境を移行するなど、ミニマムスタートから本格的なデータ活用まで、
ニーズにあったご利用方法をご提案いたします。
今日からはじめてみませんか?
AURIQの製品・ソリューションの
資料をお配りしています。
お電話でも承ります。お気軽にご相談ください。